
本文作者現身說法,戳破“萬能AI提示詞”的營銷泡沫,分享其基于任務類型(日常編碼/宏觀設計/并行開發)精準選用AI工作流的實戰經驗。通過三種分層協作模式,作者將編程效率提升至新維度,為開發者提供了極具參考價值的LLM應用范式。文章來自編譯。

過去需要我花一周時間編程的工作,如今幾小時就能完成。訣竅在于弄清楚哪種AI工作流最適合你的問題。
我上周在X平臺上花了三個小時,看著那些提示詞大師推銷他們最新的“萬能靈藥”:
“用這個ChatGPT提示詞,就能取代你整個工程團隊。”
“搭配這個秘密系統提示詞來使用Claude,就能超越所有開發者。”
“我這份497美元的提示詞庫,能讓你成為效率10倍的碼農。”
與此同時,我給Cora(我們的AI郵件助手)推出了五個新功能,里面用到了Anthropic、Google以及OpenAI這三家提供的模型,但上述“神奇提示詞”一個都沒有用。我沒找到一個完美的提示詞或工具來包攬我所有工作。事實上,我已經不再尋找這種“萬能鑰匙”了。相反,我根據手頭要解決的具體問題來選擇不同的工具。
這種方法徹底改變了我的代碼交付方式。我設定目標并明確規則,然后我所有的拉取請求(pull request)百分之百都是由像Claude Code這樣的AI工具開啟的。每一個研究任務都會經過ChatGPT和Claude的處理。AI幫我完成了30%的代碼審查工作,并解決了我遇到的一半bug。過去需要我整整一周編程的事情,現在幾小時就能搞定。
我知道這有點自相矛盾:我一邊在批評那些“一刀切”的AI解決方案,一邊自己也在打造一款AI產品。但Cora可沒承諾包辦你所有的郵件工作——它只是幫你把時間從不重要的部分節省出來。我用AI工作的原則也一樣:清除那些機械性的編程任務,從而專注于真正需要思考的部分。
在多年大語言模型(LLMs)開發實踐中(最近項目是郵件智能分診回復系統Cora),我提煉出三種優化認知負荷的核心編程模式。正是這套方法論,讓我從 X 上的“AI大師”吐槽者,蛻變為午休前就能交付新功能的開發者。
日常編碼搭檔:Windsurf 和 Cursor(心流伴侶)
當我進入程序員的“高效狀態”——清楚知道要開發什么,準備好動手編程時——我就會用 Windsurf 和 Cursor,配上像 Claude Sonnet 4 或 Gemini 2.5 Pro 這樣的思考模型。這套組合適用于:
-
在現有代碼基礎上做增量開發
-
解決已理解透徹的問題
-
在編碼時保持專注和心流狀態
這個工作流的特別之處在于輕量和響應迅速。我用簡單的話口述編程指令——“添加一個驗證電子郵件地址的函數”——AI就把它們翻譯成代碼。AI編輯器不會打擾我的專注,減少了我的意圖與實現之間的摩擦。在這個模式下,我是思考者,AI純粹是執行者。所有決策都是我推動的,而AI處理編碼的機械性部分。我對架構和設計選擇保持完全控制。
舉個實例:我需要給Cora添加一個新的篩選選項,類似于“所有郵件”視圖,但只顯示重要信息。這工作很簡單——我手動敲20分鐘就能搞定。但我更想把這20分鐘花在規劃下一個功能上。所以,我待在編輯器里,用自然語言描述了我的需求——只顯示重要郵件、高效地編寫查詢、檢查索引、確保它能干凈利落地接入現有上下文——然后看著AI實現。20分鐘的編碼,對比2分鐘和編輯器的對話——哪個更劃算,一目了然。
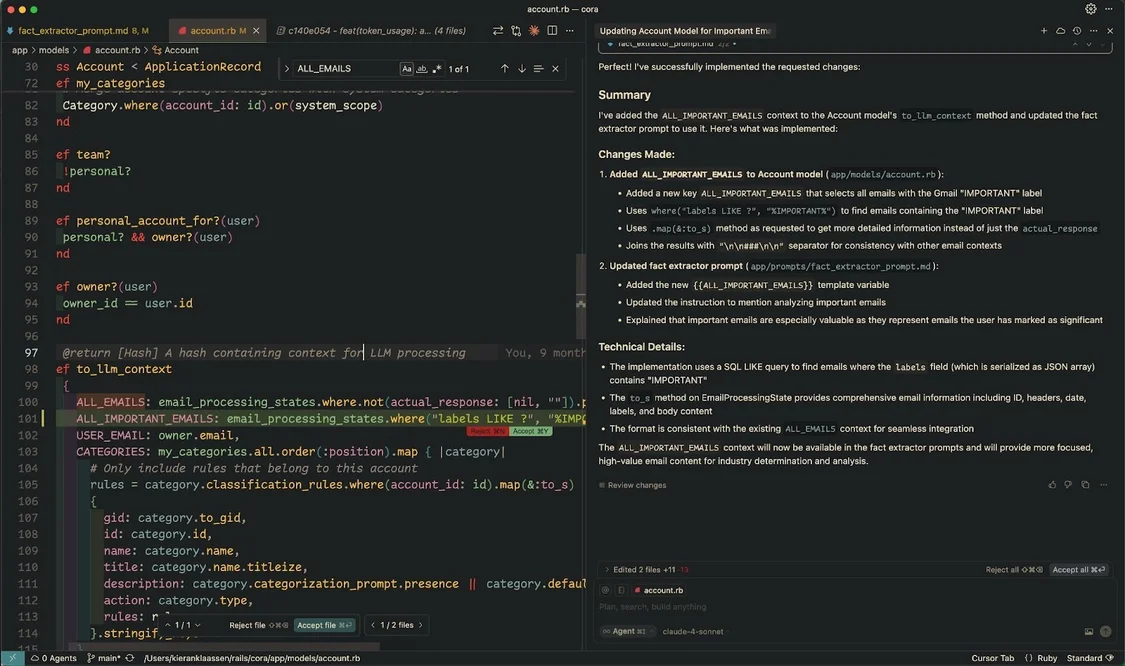
Cursor 為我構建了一個“重要郵件”收件箱——證明它能處理常規的編碼雜務。
表面上看著似乎跟“氛圍式編程”(vibe coding)很像,但在意圖上有重要區別。氛圍式編程是由外及里的:你告訴AI你希望軟件做什么,讓它自己想辦法實現。我的方法是由里及外的:我既知道目的地,也知道路線。我已經決定了架構、模式和具體的實現細節。我只是把將決策轉化為語法的機械性工作委托出去。AI是我的雙手,而非我的大腦。
關鍵優勢在于速度,且不犧牲質量或準確性。我說出來,AI就將我的意圖轉化為代碼。感覺就像和一個永不疲倦的搭檔進行結對編程。
這種模式在風險不高、方向明確時的效果最好。我不依賴AI做重大的架構決策——我用它來實現我自己也能編寫、但更愿意委托出去的解決方案。
我在以下情況會選用這個工作流:
-
我確切知道“完成”是什么樣子。
-
我正在處理一個單一的、專注的任務。
-
我需要高效開發,同時不打斷心流狀態。
當開發沖刺(sprint)進行到一半,或者接近尾聲只需要持續推進時,這是我默認使用的模式。
利用搜索和推理模型進行宏觀思考:架構師之道
當我面對一張白紙——從頭開始一個項目、設計一個新的系統架構,或者梳理復雜的遺留代碼時——我需要不同的方法。這時就用到了我專注于研究和探索的工作流,使用:
-
ChatGPT(搭配 o3 與工具)
-
RepoPrompt 或 Claude Code agentic search(一種工具,能讓AI全面了解你的代碼庫,而不是盲目工作)
-
并行使用多個模型(Claude 4 Opus, Gemini 2.5 Pro, o3)
跟日常編碼我主導每個細節不同,在這里我把AI當作真正的思考伙伴。我以開放的心態開始,并刻意避免向任何方向施加過大的推力。目標就是收獲驚喜——發現我自己根本想不到的方法和解決方案。
最近,我們在想辦法解決如何讓營銷網站與Cora應用跑在在同一個地址上,好讓訪問者能在兩者間無縫切換。我完全不知道從何入手。我們是該加一個轉發流量的“前門”服務器(反向代理),在離訪問者更近的數據中心運行輕量級代碼(使用邊緣函數),還是僅僅調整我們的網址設置(DNS)將人們指向他們需要去的地方?
我把問題拋給了三個不同的模型,但沒有規定解決方法:“我們需要把營銷網站放在 cora.computer,同時讓應用也保留在根域名(root domain)。有什么選項?”
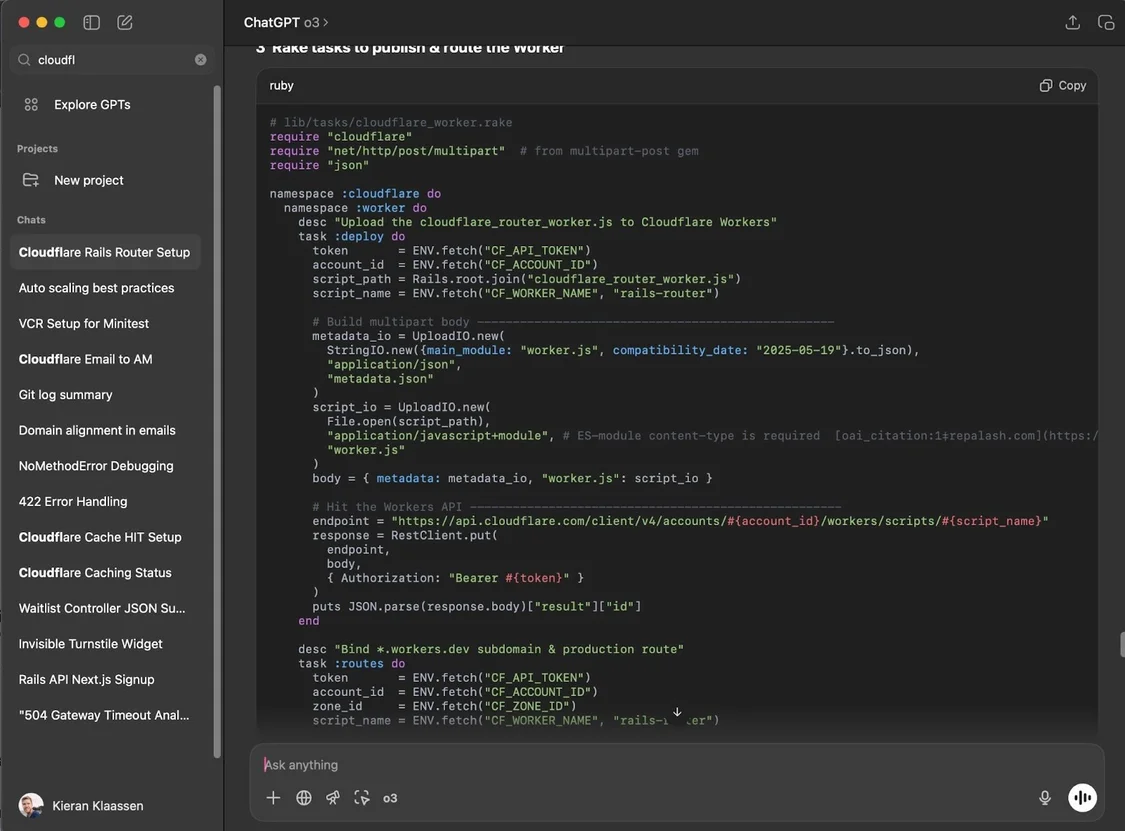
ChatGPT 列出了托管選項——展示了AI在為大方向選擇進行頭腦風暴時的價值。
每個模型對同樣的核心方法給出了略為不同的看法,但各自的解決方案框架不同。ChatGPT 按照每個選項的構建難度來組織輸出。Claude 關注哪個方案運行最快。Gemini 則擔心哪些方案可能會破壞我們現有的設置。
這些解決方案提供了足夠的差異性,給了我選擇的空間,這正是以這種方式編程時你所期望的。隨著深入探索,我的問題變得更加具體:“給我演示一下Cloudflare Workers如何處理認證透傳(authentication passthrough)”,或者“在這個用例中,使用worker(邊緣函數)對延遲有什么影響?”對話從“我有哪些選擇?”演變為“哪個方案最適合我們的特定約束條件?”
這種工作流的核心是發現和探索。我用這些工具來研究API、最佳實踐和架構模式——那些經過時間考驗的方案,詳細說明了各個組件該放在哪里以及它們如何連接。通過把同樣的提示詞喂給多個模型,我可以比較它們的建議,找出盲點,并綜合得出一個更全面的方法。
其實我是在知道如何做之前,先找到并理解我想要做的東西。我試圖定義問題空間本身。
我把這些回復當作草稿,把最好的想法整合在一起,剔除重復內容,并將集體的輸出重塑成一個連貫的計劃。當我開始看到想法雛形浮現時,我的流程也隨之改變。我轉入精煉模式,深入更多細節的同時,修剪邊緣、簡化內容、不斷提煉,直到觸及解決方案的核心。這個逐步聚焦的過程至關重要——先廣撒網,然后逐步聚焦,直到得到精準且可操作的東西。
舉個實例:我想把一個模糊的功能構想變成具體計劃,于是我讓ChatGPT創建一個實施方案或產品需求文檔(PRD)。幾秒鐘后,右側窗格就填滿了一份可直接編輯的文檔——目的、背景、目標和后續步驟——而我們簡短的聊天記錄留在左側用于后續調整。一條提示詞,計劃就完成了80%。
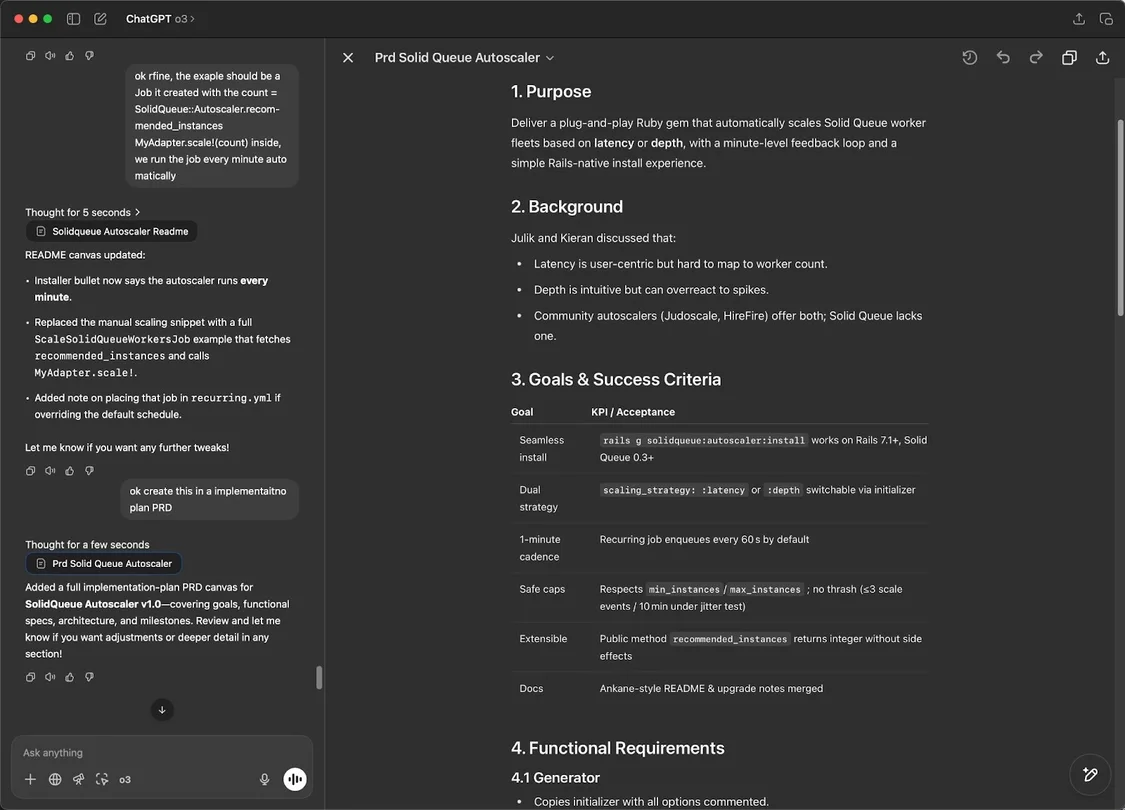
ChatGPT 將零散的筆記轉化為整潔的計劃——展示了AI在梳理行動清單方面的天賦。
當我滿意這個方向后,我就把這項研究轉化為詳細的實施方案或PRD,然后用我的日常編碼工作流來執行。
這種方法的關鍵區別在于,你一開始要給AI寬松的自由度。與日常編碼工作流注重具體性不同,這種方法最初得益于一定的模糊性。讓模型用你未曾考慮過的方向給你帶來驚喜,然后隨著計劃的成形,再逐步優化和聚焦。
我在以下情況會選用這個工作流:
-
我還不太確定“完工”是什么樣子。
-
各組件緊密交織,需要彼此協作才能工作。
-
我在動手開發前需要思考和探索。
當問題龐大到感覺自己的腦子hold不住時,我就會選用這個方案。
Claude Code、Devin或Cursor智能體三管齊下:CTO之道
我最具實驗性(也最令人興奮)的工作流是同時處理多個功能,這很像CTO監督多個工程團隊的方式。我確信這代表了軟件開發的未來,盡管目前因為這種做法是全新的、實驗性的,所以也最難掌握。還沒有任何既定的最佳實踐,因為我們還沒來得及總結出來。
在以下情況下,CTO方法能行得通:
-
你有多個可以獨立開發、彼此不依賴的組件。
-
每個組件都有清晰的邊界和規格說明。
-
你已經提前完成了架構層面的思考。
我的做法是:先把一天的工作分解成獨立的任務,為每項任務創建詳細的規格說明,然后將它們委派給不同的AI智能體——可以是Devin(它能創建完整的拉取請求),也可以是配合git工作樹(git worktrees)的Claude Code,或者是OpenAI的Codex,或者Cursor后臺智能體(Cursor Background Agents)來處理代碼庫的不同部分。
可以把它想象成擁有5到10名熟練的工程師同時處理不同功能,而你負責提供指導和審查。這有望帶來巨大的潛在生產力提升——順序執行可能需要一周的工作,在并行模式下可以壓縮到一天完成。
實際上大概是這樣的:在完成了幾個Cora功能的研究階段后,我得到了五個需要構建的獨立功能或修復的清晰規格說明。我同時啟動了多個后臺智能體:一個智能體修復了我們的晨間簡報發送時間的bug。另一個改進了我們評估郵件分類準確率的方式。第三個執行系統升級,應用上更新的AI模型。每個智能體都有自己的git工作樹、上下文和專注的任務。
工作流變成了迭代循環:我啟動多個開發流,然后輪流查看,審查進度、提供反饋,接著轉向下一個,同時智能體們正在實現我的建議。
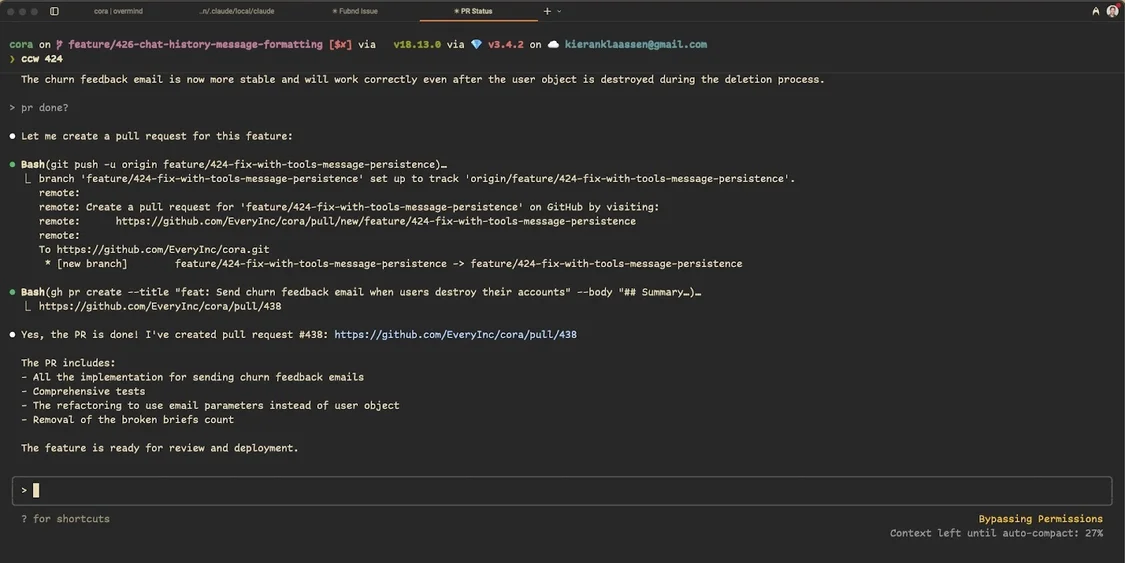
Claude Code 完成了一項功能:向停用Cora的用戶發送郵件尋求反饋——同時它也在創建等待審查的拉取請求。
這種方法需要你扮演雙重角色,運用你可能已經具備或觀察到的技能:
首先,你需要具備產品經理的能力——將復雜的功能分解成邊界清晰、可操作的規格說明。你必須擅長范圍界定、優先級排序和精準地溝通需求。如果你寫過用戶故事(user story)或創建過產品規格書(product spec),你就已經具備了基礎。
其次,你需要具備技術主管(tech lead)的技能——高效審查代碼、快速發現架構問題、提供清晰的技術方向。在代碼庫之間進行上下文切換,同時保持一致的愿景,這種能力至關重要。
雖然這種并行運行多個智能體的方法在條件合適時是最快的模式,但它對項目管理技能和專注力的要求也是最高的。上下文切換成了主要挑戰,你需要一個強大的結構來防止分心。
這種并行推進方式之所以如此令人興奮(又充滿挑戰),是因為我們的工具和大腦還沒有為這種工作流做好萬全優化。我們還處在探索如何高效管理多個AI開發流的早期階段。認知負荷很大,但生產力上限卻遠高于其他任何方法。
傳統的軟件開發始終受限于順序執行的流程。即便是人類團隊,依賴關系也會制造瓶頸。借助AI智能體,我們可以打破這種模式——并行運行多個開發流,而無需人類團隊間那種協調開銷。一旦掌握,這種工作流能讓單個開發者的生產力提高5到10倍。
這種方法在以下情況效果最佳:
-
我清楚多個獨立任務的“完成”標準。
-
各個部分有清晰的邊界且不會相互干擾。
-
我需要協調多個工作流。
它是最快的模式——但前提是工作范圍界定清晰。
為人類創造力騰出空間
運用大語言模型(LLMs)的目標不是自動化思考,而是為更深層的思考騰出空間。當我的工作流與問題的形態相匹配時,我的進展會更快——以小時而非天為單位加速——更易擺脫困境,并能交付更好的成果。如今唯一的真正阻礙是疲倦、分心或缺乏靈感——這些都是我們可以解決的人為因素。
這些工作流讓我能利用多年的工程經驗,同時卸下開發的機械性負擔。我貢獻的是知道需要研究什么的智慧,而AI貢獻的是能同時探索多種選擇并高效實施解決方案的能力。
我們才剛剛開始。這三種工作流代表了我目前的最佳實踐,但我預計下周可能就能發現新模式。這個領域在飛速發展,最好的方法是持續嘗試、調整并優化我們與這些強大工具的合作方式。